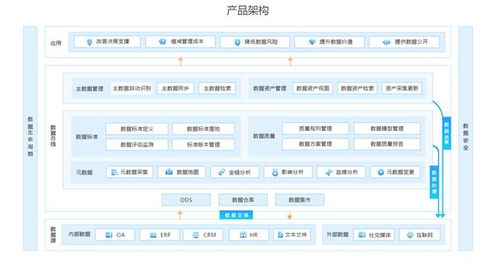
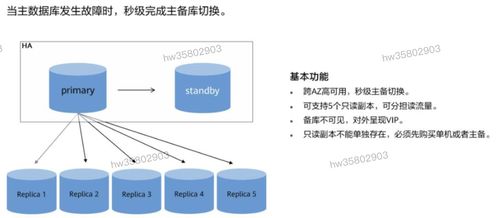
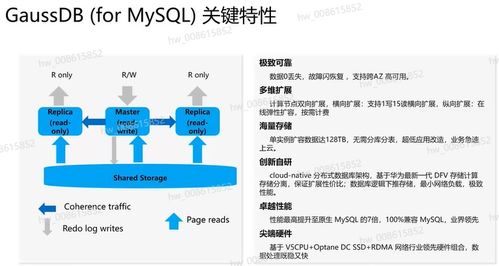
在數字化教育蓬勃發展的今天,數據已成為驅動業務增長與優化用戶體驗的核心資產。有道精品課作為網易有道旗下的優質在線教育品牌,面對海量、多源、異構的業務數據,構建一個統一、高效、智能的數據中臺勢在必行。其中,數據處理服務作為數據中臺的“中樞神經系統”,承擔著從原始數據到可用資產的轉化重任,是釋放數據價值的關鍵環節。
一、 數據處理服務的定位與挑戰
有道精品課的數據處理服務,旨在構建一個覆蓋數據接入、清洗、集成、計算、存儲與服務的全鏈路、標準化流水線。其核心目標是打破數據孤島,將分散在課程、用戶、營銷、互動等各業務系統的數據統一處理,形成高質量、可復用的數據資產,為上層的數據分析、用戶畫像、智能推薦、運營決策等應用提供可靠支撐。
面臨的挑戰主要包括:
- 數據源復雜:數據來自APP端、Web端、服務器日志、第三方系統等多個渠道,格式與標準不一。
- 實時性要求高:如用戶實時學習行為追蹤、課程推薦等場景,需要低延遲的數據處理能力。
- 數據質量保障:需確保數據的準確性、一致性與完整性,避免“垃圾進,垃圾出”。
- 規模與成本:隨著用戶量與課程量的快速增長,數據處理系統需具備彈性伸縮能力,同時控制計算與存儲成本。
二、 數據處理服務的核心架構實踐
有道精品課的數據處理服務采用了分層、解耦的架構設計,主要包含以下關鍵層次:
1. 統一接入層:
- 建立了標準化的數據接入規范,對各類數據源進行抽象。通過Agent、SDK、API等多種方式,將日志、業務數據庫Binlog、埋點數據等實時或批量接入到消息隊列(如Kafka)中,實現數據的緩沖與解耦。
2. 計算處理層(核心):
- 批處理鏈路:基于Hadoop/Spark生態,構建了T+1的離線數據處理管道。負責處理對時效性要求不高的海量歷史數據,進行復雜的ETL(抽取、轉換、加載)、數據建模(如數據倉庫的維度建模)、指標聚合等任務,形成主題域清晰的數據集市。
- 流處理鏈路:基于Flink/Spark Streaming構建實時計算管道。對消息隊列中的數據進行實時消費,實現秒級或分鐘級的用戶行為事件處理、實時指標計算(如在線人數、課程點擊熱力圖)和實時特征提取,為實時推薦、風控預警等場景提供動力。
- Lambda/Kappa架構融合:在實踐中,結合了批流一體的思想,通過統一的元數據管理和數據血緣追溯,確保批處理與流處理結果的一致性,并能在必要時進行互為補充與修正。
3. 存儲與服務層:
- 根據數據的熱度、查詢模式和應用場景,采用混合存儲策略。原始明細數據存入HDFS或對象存儲;處理后的結構化數據存入OLAP引擎(如ClickHouse、Doris)供高速分析查詢;維度模型數據存入Hive/數據倉庫;實時特征和結果數據可存入Redis/HBase等KV存儲以供在線服務低延遲調用。
- 通過統一的數據服務API網關,將處理好的數據資產以接口、數據文件、OLAP查詢等多種形式,安全、高效地提供給業務方、分析師和算法工程師使用。
4. 數據質量與運維管控平臺:
- 貫穿整個處理流程,內置了數據質量監控規則(如完整性、唯一性、準確性校驗)、任務調度與依賴管理、資源監控告警、數據血緣圖譜和故障快速定位等能力,保障數據處理流程的穩定、可靠與透明。
三、 實踐帶來的核心價值
- 效率提升:通過標準化、自動化的數據處理流水線,將數據研發人員從繁瑣、重復的ETL工作中解放出來,數據需求交付周期大幅縮短。
- 質量可靠:統一的數據質量標準和監控體系,確保了數據資產的準確可信,為精細化運營和科學決策奠定了堅實基礎。
- 賦能業務創新:高質量、易獲取的實時與離線數據資產,直接賦能了多個業務場景:
- 個性化學習:基于用戶行為實時數據,構建動態用戶畫像,實現課程、習題、內容的精準推薦。
- 精細化運營:實時監控課程訪問、完課率、互動情況等核心指標,助力運營團隊快速調整策略。
- 商業分析:通過整合的銷售、用戶、課程數據,深入分析轉化漏斗、用戶生命周期價值(LTV),指導產品與市場策略。
- 成本優化:統一的資源調度與存儲治理,避免了煙囪式開發帶來的資源浪費,實現了計算存儲資源的集約化管理和成本控制。
四、 未來展望
有道精品課的數據處理服務將繼續向更智能、更敏捷的方向演進:
- 智能化:引入AI技術,實現數據質量的智能診斷與修復、ETL任務的自動生成與優化。
- 服務化與自助化:進一步降低數據使用門檻,提供更強大的自助數據分析工具和更豐富的數據產品,讓業務人員能更直接、靈活地探索和利用數據。
- 實時化深化:拓展流處理的應用邊界,在更多業務場景中實現實時感知、實時決策與實時干預。
有道精品課通過構建堅實、靈活的數據處理服務,不僅解決了當下數據治理的痛點,更打造了面向未來數字化競爭的核心數據能力,為在線教育業務的持續創新與增長提供了源源不斷的“數據燃料”。